En science, toutes les études ne se valent pas et apportent chacun des niveaux de preuve différents. Elles possèdent des structures et des compositions différentes qu’il faut connaître pour mieux maîtriser la valeur d’une étude scientifique. Explications.

Sommaire
Comprendre la hiérarchie des preuves scientifiques
« Une étude a montré que le traitement du professeur Dupont était efficace contre la maladie X »
Ce genre de phrase pullule dans la presse, dans les unes des journaux, ou encore dans les débats entre initié et non-initié.
Je vous avais présenté dans un billet précédent l’architecture ou les entrailles d’une étude scientifique. Les « papiers » comme on dit dans le jargon avec l’introduction, la méthode, les résultats et la discussion finale.
Si on peut ranger tous les travaux derrière le terme générique « d’étude scientifique », toutes ne se ressemblent pas. Bien au contraire. Nous avons une tripotée d’études avec des architectures différentes qui n’apportent pas le même niveau de preuves et ne mesurent pas la même chose.
L’actualité brûlante avec le coronavirus nous a montré que certains essais cliniques étaient plus sérieux que d’autres. Voici donc un rappel important sur les différents niveaux de preuves en science.
Ce rappel majeur vous permettra de mieux décrypter la qualité d’une étude scientifique et ses implications en fonction de son architecture (son design), avec par exemple les fragiles études de cas-contrôle contre les sérieux essais randomisés en double-aveugle.
La pyramide des preuves
Ce genre de pyramide s’est répandu comme une traînée de poudre pour classer la force des preuves scientifiques. On retrouve souvent les méta-analyses et les revues systématiques tout en haut. Les méta-analyses représentant le Graal de la recherche scientifique.
Les essais cliniques contrôlés et interventionnels occupent la seconde marche, avec les études de cohorte ou épidémiologiques et les études de cas, rapports d’experts, etc.
Pour compliqué le tout, on retrouve bien sûr dans chaque catégorie des sous-catégories en fonction de la qualité des études, de la méthode, de l’indépendances des auteurs, etc.

Vous découvrirez en fin d’article une critique de cette pyramide qui ne reflète pas réellement la manière la plus correcte d’analyser et de classer ces preuves scientifiques. Cette pyramide est un raccourci un peu trompeur qui mérite certaines nuances pour être plus adapté.
Comprendre ces nuances est une étape importante dans l’accès à l’information médicale et scientifique, et dans le développement d’un esprit critique finement aiguisé. Comprendre ces nuances en science permet de mieux se positionner dans l’actualité et de se détacher d’arguments parfois vaseux (comme « le bon sens ») ou les biais divers et variés (confirmation, du survivant, etc.)
Comprendre une étude scientifique. Si vous voyez souvent passer des articles de la presse disant “une étude dit que…” sans vraiment savoir ce que sont ces études. Voici un article pour découvrir les entrailles, pas si mystérieuses que ça, des fameuses études scientifiques.
 Comprendre une étude scientifique. Si vous voyez souvent passer des articles de la presse disant “une étude dit que…” sans vraiment savoir ce que sont ces études. Voici un article pour découvrir les entrailles, pas si mystérieuses que ça, des fameuses études scientifiques.
Comprendre une étude scientifique. Si vous voyez souvent passer des articles de la presse disant “une étude dit que…” sans vraiment savoir ce que sont ces études. Voici un article pour découvrir les entrailles, pas si mystérieuses que ça, des fameuses études scientifiques.Le top : essai clinique contrôlé (avec ou sans méta-analyse)
Quand on cherche à se rapprocher le plus possible de la vérité, ou autrement dit des effets les mieux cernés sur la santé (positif comme négatif), on doit prendre en compte les essais cliniques randomisés.
Les fameux randomized clinical trial (RCT en anglais) représentent le sommet de la pyramide des preuves scientifiques, ceux qui minimisent le plus le risque de biais. Mais ces risques existent toujours bien entendu. L’art réside ensuite dans l’analyse de chaque essai clinique, d’interpréter toutes les évidences scientifiques, les besoins des patients, et de prendre en compte la réalité du terrain.
On pourra rajouter à ces RCT toutes les mesures de précautions additionnelles qui renforcent la validité des résultats :
- du double aveugle. Les patients ne savent pas s’ils vont prendre un placebo ou un traitement actif, et les expérimentateurs ne savent pas quel patient est dans quel groupe. C’est un critère de rigueur supplémentaire, car il permet de réduire le risque de biais, ou certaines manipulations des données si on a connaissance de qui a quoi (surtout si on a envie de montrer que son traitement fonctionne !)
- du multi-centrique. On réalise le même essai clinique dans différents centres médicaux du monde entier. Cela renforce la généralisation des résultats avec des ethnies différentes par exemple, et réduit le risque de biais.
- du placebo. Les essais cliniques possèdent par nature un groupe contrôle qui sera comparé au groupe testant la molécule ou la thérapie ciblée. Ce groupe contrôle devrait être traité par un placebo.
- De nombreux participants. Un essai clinique sur 40 patients masculins n’aura pas le même impact ni la même force qu’un autre avec 300 représentants de chaque sexe. Donc oui, d’une certaine manière, la taille est importante dans les essais cliniques !
Tous les essais cliniques ne sont pas randomisés, c’est à dire avec une création de groupes comparables dès le départ, ni conduits en aveugle. On parle d’open label pour ces études où les expérimentateurs et les patients savent ce qu’ils prennent.
Autrement dit, tous les essais cliniques ne représentent pas le Saint-Graal de notre médecine et science moderne.

Le Graal avec les méta-analyses
Analyser toutes les études cliniques globalement est la tendance générale pour produire des résultats solides. Les méta-analyses sont de puissants outils, mais également des dangers dans l’interprétation des preuves scientifiques.
Ces méta-analyses permettent d’étudier globalement les résultats de plusieurs essais cliniques, pour dégager une tendance, surtout face à des études discordantes. Mais tout dépend de ce qu’on décide d’analyser et ce qu’on décide de laisser de côté.
Une méta-analyse remplie d’études moyennes, avec des biais importants, sera nécessairement moins intéressante et moins pertinente que sa cousine conduite sur des essais cliniques randomisés en double aveugle par exemple.
?
L’hétérogénéité des études incluses dans les méta-analyses est aussi un facteur important. La méta-analyse la plus rigoureuse essayera de prendre en compte des essais cliniques les plus homogènes possible. Plus cette hétérogénéité augmente plus les risques de biais dans la réalisation des études fort et plus l’interprétation finale sera vacillante.
 L’hétérogénéité des études incluses dans les méta-analyses est aussi un facteur important. La méta-analyse la plus rigoureuse essayera de prendre en compte des essais cliniques les plus homogènes possible. Plus cette hétérogénéité augmente plus les risques de biais dans la réalisation des études fort et plus l’interprétation finale sera vacillante.
L’hétérogénéité des études incluses dans les méta-analyses est aussi un facteur important. La méta-analyse la plus rigoureuse essayera de prendre en compte des essais cliniques les plus homogènes possible. Plus cette hétérogénéité augmente plus les risques de biais dans la réalisation des études fort et plus l’interprétation finale sera vacillante.Les autres études beaucoup moins top
Au-delà du Saint-Graal de l’essai clinique randomisé et contrôlé, qui peut coûter cher et n’est pas accessible à toutes les équipes non plus, on retrouve bien sûr toute une panoplie de différentes méthodes scientifiques. Cette liste n’est pas exhaustive, loin de là, mais tente de détailler les principales pour mieux comprendre les limites et le risque de biais.
C’est comme un couteau suisse scientifique avec différents outils, qui ont tous des qualités et des faiblesses, et un rôle particulier à jouer pour mieux comprendre notre monde.
L’essai clinique non contrôlé
Ce genre d’études se produisent régulièrement, avec une puissance moins importante que les cousines contrôlées et randomisée, puisqu’elles ne possèdent pas de groupe contrôle.
Il y a bien sûr des raisons pratiques évidentes à conduire ce genre d’étude (moins chère et moins contraignante), mais aussi éthiques quand des maladies graves sont étudiées (par exemple avec le cas d’Ebola).
En 2010, Luigi Saccà, du département de médecine interne en Italie, précisait qu’au moins 2 essais cliniques sur 3 étaient contrôlés. Il nous rappelle que les raisons peuvent être nombreuses pour choisir l’essai non contrôlé plutôt que l’autre.
Par exemple, l’étude d’une maladie si rare qu’il est impossible de former deux groupes de taille suffisante, ou encore dans le suivi d’une intervention vitale pour les patients comme les transplantations d’organes.
Étude prospective
C’est le grand classique en nutrition. On va créer deux grands groupes d’individus, souvent des dizaines de milliers, et les suivre pendant des mois et des années.
Les chercheurs vont devoir s’appliquer à noter avec le plus de minuties les habitudes de vie, alimentaires, et l’objet scientifique de l’étude : la survenue d’une maladie, d’un cancer, ou autre chose.
Ce sont les études de prédilections quand on veut mesurer l’effet d’une alimentation sur le risque cardiovasculaire par exemple. La puissance de ces études va dépendre de la qualité du suivi (en temps et en précision), de l’échantillonnage, de la surveillance et de l’inclusion des biais.
Ce sont ces études-là qui permettent de sortir des chiffres sensationnels dans la presse. 12% de risques de mourir en moins en évitant la viande rouge transformée ou encore 15% de risque de cancer en moins avec une alimentation biologique.
Ces études sont généralement issues de grand suivi national comme les fameuses cohortes américaines NAHNES ou encore The Health Professionals Follow-Up Study (HPFS).
Étude rétrospective
Ce sont des études de cohortes aussi, comme les prospectives, mais cette fois-ci on regarde dans le passé au lieu de suivre des gens. On va créer des groupes, essayer de contrôler les facteurs de confusions et s’intéresser à des problèmes de santé en lien avec des habitudes de vie dans le passé.
Ces études sont moins fiables et exposent à plus de biais, car on va essayer de retracer le passé des participants sans avoir établi de suivi au préalable, de protocole, de questionnaires, etc.
Cancer des poumons chez les non-fumeurs ? Vous avez par exemple cette grande étude rétrospective qui a voulu savoir chez des millions de Sud-Coréens sans cancer des poumons qu’elles étaient leur caractéristique et habitude de vie. Autrement dit, trouver les facteurs de risque qui étaient dans ce cas présent la consommation d’alcool, l’indice de masse corporel, l’exercice et une alimentation basée sur la viande.
Ces études de cohortes, prospective (vers le futur) et rétrospective (vers le passé), ne permettent pas d’établir des liens de cause à effet, mais des associations.
 Ces études de cohortes, prospective (vers le futur) et rétrospective (vers le passé), ne permettent pas d’établir des
Ces études de cohortes, prospective (vers le futur) et rétrospective (vers le passé), ne permettent pas d’établir des Étude de cas-contrôle
On parle de « case control study » en anglais, et on descend une nouvelle fois dans la hiérarchie de la qualité des preuves scientifiques avec ce type d’étude observationnelle très courante, qui ne nécessitent pas un gros budget et des moyens importants.
Ce type d’étude part d’une maladie (par exemple le cancer de poumons) ou de n’importe quel autre paramètre et de deux groupes d’individus qui l’ont ou pas, avec une remontée dans le temps pour tenter de trouver les facteurs susceptibles d’être responsable de l’apparition de l’observation initiale.
La méthode se rapproche d’une étude rétrospective, mais pour l’étude cas-contrôle, elle ne permet pas de déterminer l’incidence ou la prévalence de l’éventuelle maladie.
Ces études permettent de toucher du doigt des facteurs de risque suspecté (comme avec les célèbres études de cas-contrôle entre le risque de cancer du poumon et le tabagisme) et de les étudier plus en détail avec des protocoles plus précis.
Études de cas
C’est tout simplement l’étude d’un cas médical (ou d’un autre sujet) en profondeur qui porte un intérêt, les « case series » en anglais. Par exemple, je parlais dans un précédent billet des guérisons naturelles du cancer avec des études de cas très intéressantes de régression spontanée de métastases ou autres.
Ces études permettent de documenter avec précision des cas rares ou des signaux nouveaux sur une affection ou autre.
On est bien sûr dans un niveau de preuve très bas avec basiquement un échantillonnage souvent d’une seule et unique personne.
Avis d’experts
En l’absence d’études scientifiques sérieuses et rigoureuses, c’est la recommandation d’un groupe d’experts qui peut faire office de recommandation générale. Cet avis se base sur différents niveaux de preuves
Les lettres à l’éditeur
C’est une autre manière de pouvoir exprimer scientifiquement son avis dans un journal. On peut adresser à l’éditeur d’un journal une lettre, avec des normes sur le nombre de caractères, de publications que l’ on peut citer. Les lettres à l’éditeur ne représente pas des niveaux de preuves scientifiques élevés.
En tout cas elles ne doivent pas servir pour établir des recommandations de pratiques cliniques.
Il existe aussi les « opinions », les « mini-review », les « short communications », etc, etc. Il y en a pour tous les goûts.
Un résultat doit avant tout être cliniquement significatif. Faisons le point sur l’importance de cette différence.
Revues narratives versus revue systématique.
C’est un autre point très intéressant et informatif dans la qualité des preuves scientifiques. Les chercheurs produisent des synthèses régulièrement sur des sujets qui ont eu suffisamment d’études publiées pour faire tout simplement le point. On parle de synthèse.
Mais toutes les synthèses ne se valent pas. Il y a dans un premier temps les synthèses dites narratives de la littérature. Un travail qui manque de cadre, d’un protocole précis de sélection des études publiées et de l’analyse des auteurs. Autrement dit, les biais dans le choix des études, l’analyse et l’interprétation sont tout à fait possibles.
Les synthèses narratives peuvent être utiles pour prendre connaissance de l’état de l’art dans un domaine, mais il faut faire attention à la méthode suivie par les auteurs et bien sûr les éventuels conflits d’intérêts qui pourraient déformer la réalité de certaines études, et omettre les plus dérangeantes.
C’est pour cette raison que nous avons dans un second temps des synthèses plus solides, plus encadrées et qui permettent de produire un très haut niveau de preuve scientifique : ce sont les revues systématiques.
Derrière ce mot se cache une procédure qui permet de clarifier la sélection des études scientifiques, de les analyser selon des tableaux et des échelles d’évaluation publiés et connus et permettent aussi de faire les célèbres méta-analyses.
Donc si on vous sort une étude comme étant une bonne preuve pour soutenir un point précis, car c’est une synthèse de la littérature scientifique, il faut que ce soit une revue systématique des études, et idéalement accompagné d’une méta-analyse.
Simpliste pyramide des preuves ?
Dans la réalité, la pyramide des preuves qu’on vous présente partout est fausse. J’y vais fort, mais elle est tellement simpliste et générale, qu’elle ne s’applique plus vraiment aux nombreuses particularités du milieu médical.
Car les faits sont têtus. Une méta-analyse d’études observationnelles n’aura absolument pas le même niveau de force qu’une même synthèse d’essai clinique ! Autrement dit : un seul essai clinique est parfois plus informatif et pertinent que toutes les méta-analyses sur des études de faibles qualité.
D’où l’évolution de la pyramide :

La frontière entre les différentes cases est en réalité fluctuante.
Avec cette nouvelle version de la pyramide des preuves, on peut zoomer sur une partie (totalement arbitraire) de celle-ci et réaliser que parfois, l’essai clinique sera supérieur aux méta-analyses. Tout va dépendre à la fois de la qualité de l’essai clinique d’une part, et de la méta-analyse d’autre part.
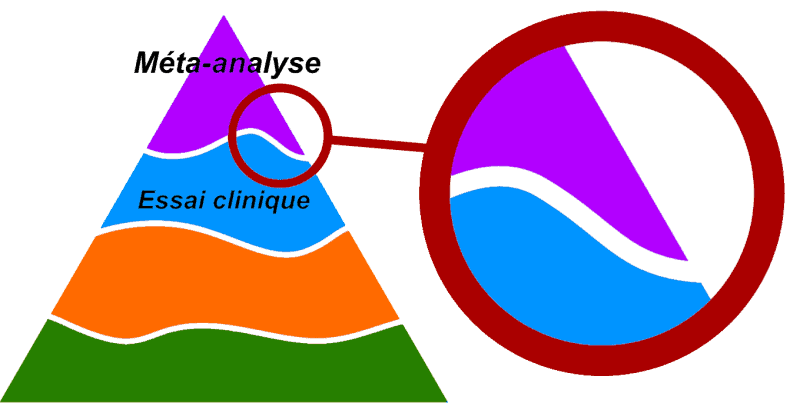
Et encore, cet ajustement ne corrige pas tout. Car tous les domaines de la médecine n’ont pas vocation à utiliser le même type d’étude pour avoir les meilleurs réponses.
Classiquement, l’essai clinique contrôlé en aveugle et contre placebo représente le Graal de l’évaluation thérapeutique. Dans cette catégorie, le sommet de la pyramide pourrait être partagé par du bleu et du violet.
Le Graal du Graal représente la méta-analyse des essais cliniques de qualité. Une prestation souvent réalisée par la Collaboration Cochrane.
Les études de cohorte à grande échelle et sur de longue période de temps seront particulièrement adapté pour étudier les effets indésirables (et parfois désirables) rares de certains médicaments (on pourrait parler de pharmaco-épidémiologie).
Les recommandations globales en pratique clinique pourront aussi s’appuyer sur différents niveaux de preuves, pour en vérifier la cohérence et donc la force du signal.
En résumé, les pyramides qu’on vous présente habituellement sont simplistes et pourraient faire croire qu’une méta-analyse est la toute puissance divine. Alors que non. Des méta-analyses même conduites sur des essais cliniques peuvent être de très mauvaise qualité et servir des intérêts nauséabonds.
Conclusions
La science n’est pas représentée par qu’un seul type d’étude, bien au contraire, des dizaines de design différents existent et peuplent les journaux scientifiques avec des réponses et des fiabilités différentes.
Une étude de cohorte ne doit pas être balayée du revers de la main, car ce n’est pas un essai clinique randomisé, qui ne permet pas de faire de lien de cause à effet. D’excellentes études prospectives apportent des informations très intéressantes si l’ensemble de la méthode est rigoureuse et l’analyse menée sérieusement (idéalement par des équipes indépendantes et reproduites ailleurs), avec toute la prudence nécessaire pour l’interprétation.
Ce qu’il faut également savoir c’est que presque chaque département en science ou grande association médicale possède sa propre hiérarchie des preuves scientifiques. Même si tout le monde s’accorde sur les grandes lignes, celles que je viens de vous délivrer, des nuances peuvent exister dans les grades, les codes, le classement.
Vous avez ici une liste de différentes hiérarchisations des preuves scientifiques, en fonction des domaines et des auteurs, qui placent bien souvent les essais cliniques contrôlés avec beaucoup de participants au sommet de la pyramide.
Ou encore celle-ci qui présente les différents niveaux d’évidences scientifiques selon le centre d’Oxford de la médecine basée sur les preuves.
Ces outils sont complexes et moi-même je ne connais pas ni ne maîtrise toutes les notions et les variations de toutes les études. Mais vous avez dans cet article une base pour comprendre les notions essentielles de hierarchisations des études scientifiques.
3 commentaires
Articles toujours très intéressants et très fouillés.
Les études randomisées pour mettre en évidence des événements peu fréquents doivent avoir des effectifs importants.
Il me semble que l’effectif de chaque groupe test et placebo devrait être 20 fois le dénominateur de la probabilité d’un évènement. Par exemple si la probabilité est 1/100 l’effectif des groupes devrait être 2000 (20×100). En effet, en dessous, la probabilité qu’il y ait une mauvaise répartition des individus sujets à l’évènement est non négligeable. Sauf erreur pour 1/100 et des groupes de 100, la probabilité que les deux individus sujets à l’évènement soient dans le même groupe est de 50%.
Bonjour Roger,
Oui, vous avez raison.
Il existe des formules mathématiques pour déterminer l’échantillon nécessaire pour démontrer un effet statistiquement significatif en fonction de la taille de l’effet recherché.
C’est pour cette raison qu’il faut énormément de participants pour des effets faibles !
On parle surtout de puissance statistique pour pouvoir démontrer un effet. On peut faire une bonne randomisation avec peu de participants. Même moins de 30 participants par exemple.